
Custom exclusions for Zappa deployment packages via zip callbacks
Background
I am currently using Zappa to manage a suite of lambda functions I have running on Amazon Web Services (AWS) to support a slack application I built; domi. If you aren’t familiar with Zappa, it vastly simplifies the process of creating, deploying and updating lambda functions using a Python runtime. You can learn more from the zappa blog or the slides from a talk I gave at a Toronto Python meetup.
The configuration for each function is stored in the project’s zappa_settings.json config file. I currently have 3 different lambda functions running to support my project. As a result, my zappa_settings.json looks something like this:
{
"app": {
"app_function": "domi.app.app",
"aws_region": "us-east-1",
"slim_handler": true,
"project_name": "domi",
"runtime": "python3.7",
"s3_bucket": "domi",
"domain": "apartments.domi.cloud",
"keep_warm": true,
"keep_warm_expression": "cron(0/3 12-4 ? * * *)",
"timeout_seconds": 3,
"exclude": [
"*.jpg", "*.jpeg", "*.ipynb", "*.mov", "*.gif", "*.mp4",
"secrets.json", "*.csv", "*.pickle", "*.ann"
],
// ...
},
"batch": {
// ...
"slim_handler": true,
"events": [
{
"function": "domi.apartments.get_all_listings",
"expression": "cron(0 */2 * * ? *)" // run every 2 hours
},
{
"function": "domi.apartments.process_new_listings",
"expression": "cron(0 * * * ? *)" // run every hour
},
{
"function": "domi.apartments.check_listing_statuses",
"expression": "cron(0 * * * ? *)" // run every hour
}
],
"timeout_seconds": 900,
// ...
},
"price_rank": {
// ...
"slim_handler": true,
"events": [
{
"function": "domi.apartments.price_rank",
"expression": "cron(0 */2 * * ? *)" // run every 2 hours
}
],
"memory_size": 3000, // 3 GB
"timeout_seconds": 900,
// ...
}
}
1) app: This is the flask app powering both the domi site and all the slack interactions. This function needs to be fast and responsive, hence the "keep_warm": true setting to deal with lambda cold starts and the short timeout setting, the amount of time that Lambda allows a function to run before stopping it, of 3 seconds.
2) batch: This lambda runs all batch processes required by domi, like grabbing all new listings & processing them, or checking the status of existing listings. These processes take longer to run, so I have the max runtime set to 15 minutes ("timeout_seconds": 900).
3) price_rank: This lambda runs a batch job to calculate price rank scores for each listing. More RAM is required for this function since it must store all active listings for calculating nearest neighbours. To save on costs, this was moved to a separate function sine the other batch processes don’t need 3GB of RAM.
The Problem
Even after excluding larger CSV, image & video files via the exclude setting, I am still above the lambda deployment size limit due to the large python packages required for the price rank algorithm (pandas, numpy, scipy, matplotlib, PIL).
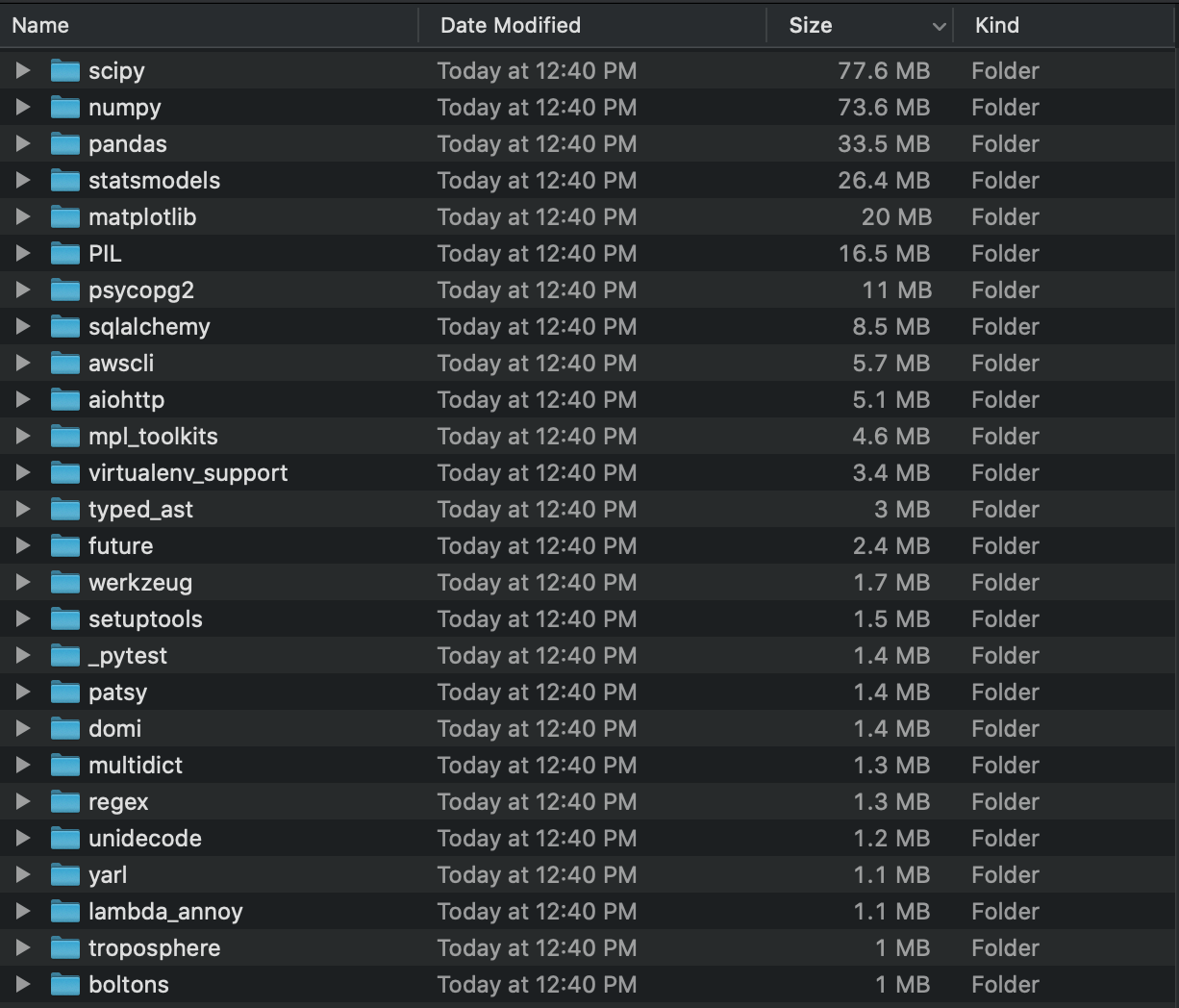
To get around this, I use Zappa’s slim handler setting ("slim_handler": true), which pulls down the dependencies from S3 at run time. This comes at a cost, since pulling down the required packages from S3 increases your startup time. For a warm lambda function, this isn’t a problem, but when a bunch of new lambdas are being created in response to increased traffic (and hence going through the cold start), the longer response times become noticeable. Additionally, the deployment time is drastically increased as a file well over 100MB must be uploaded to AWS, which is especially problematic on bad wifi.
Ideally, I could exclude all the large packages not required in the app and batch lambdas to get my deployment package under the size limit, and leave them in for the price_rank lambda. Intuitively, you’d think something like "exclude": ["pandas", "numpy", "scipy"] or "exclude": ["*pandas*", "*numpy*', "*scipy*"] would do the trick. But, Zappa currently does not provide support for directly excluding directories (read python packages) as discusssed here.
Solution
Luckily, Zappa was designed to handle flexible workflows by allowing for custom Python functions to be invoked at different stages of the deployment process. As of the time of this writing, Zappa supports the following callbacks:
"callbacks": { // Call custom functions during the local Zappa deployment/update process
"settings": "my_app.settings_callback", // After loading the settings
"zip": "my_app.zip_callback", // After creating the package
"post": "my_app.post_callback", // After command has executed
}
For this use case, we’ll leverage the zip callback and run a function that removes unwanted packages from the deployment package prior to uploading. When Zappa callbacks are invoked, the Zappa cli class instance is passed as a parameter. As a result, we can leverage the zip_path class attribute to grab the path of the deployment package. Additionally, since Zappa does not perform any config file parameter validation, we can add an additional attribute to the zappa_settings.json file, regex_excludes, and access that via the zappa_settings class attribute. We’ll use the regex_excludes attribute to specify a list of regular expressions for files and/or directories we want to exclude.
Here’s what I’ve added to the zappa_settings.json for the app and batch functions which don’t require these Python packages.
"regex_excludes": [
"pandas", "scipy", "numpy", "PIL", "statsmodels", "matplotlib"
],
"callbacks": {
"zip": "zappa_package_cleaner.main"
},
"slim_handler": false // don't need slim handler anymore...
The callback invokes the main function defined in zappa_package_cleaner.py which lives at the root of my project.
def main(zappa):
"""Clean up zappa package before deploying to AWS
Args:
zappa (ZappaCLI): ZappaCLI object from zappa/cli.py. Automatically
gets passed in by callback initiation.
"""
print("Running zappa package cleaner")
zip_filename = zappa.zip_path
stage_settings = zappa.zappa_settings.get(zappa.api_stage, {})
excludes = stage_settings.get("regex_excludes", None)
if not excludes:
raise Exception(f"No regex_excludes provided for stage: {zappa.api_stage}")
if zip_filename.endswith(".tar.gz"):
archive_format = "tarball"
extension = ".tar.gz"
elif zip_filename.endswith(".zip"):
archive_format = "zip"
extension = ".zip"
else:
raise Exception("Archive extension must be .zip or .tar.gz")
zip_filepath = os.path.join(os.getcwd(), zip_filename)
temp_unarchive_path = os.path.join(os.getcwd(), zip_filename.replace(extension, ""))
unpack_archive(zip_filepath, temp_unarchive_path)
remake_archive(temp_unarchive_path, zip_filepath, archive_format, excludes)
print(f"Removing {temp_unarchive_path}")
shutil.rmtree(temp_unarchive_path)
This function does the following:
1) Grabs the list of regular expressions from regex_excludes
2) Unpacks the archive to a temporary directory
3) Remakes the archive, excluding any files that match any of the exclude regexes
for root, dirs, files in os.walk(temp_unarchive_path):
for filename in files:
filepath = os.path.join(root, filename)
if any(re.search(exclude_regex, filepath) for exclude_regex in excludes):
continue
4) Removes the temporary directory
You can view the full zappa_package_cleaner.py module in this gist.