
Tracking state with type 2 dimensions
- Background & Motivation
- Options for tracking state
- Type 2 modelling recipes
- Gotchas, lessons learned & the path forward
- Appendix: SQL Query Recipes
Application databases are generally designed to only track current state. For example, a typical users data model will store the current settings for each user. Each time they make a change, their corresponding record will be updated in place:
| id | feature_x_enabled | created_at | updated_at |
|---|---|---|---|
| 1 | true | 2019-01-01 12:14:23 | 2019-01-01 12:14:23 |
| 2 | false | 2019-01-01 15:21:45 | 2019-01-02 05:20:00 |
This makes a lot of sense for applications. They need to be able to rapidly retrieve settings for a given user in order to determine how the application behaves. An indexed table at the user grain accomplishes this well.
But, as analysts, we not only care about the current state (how many users are using feature “X” as of today), but also the historical state. How many users were using feature “X” 90 days ago? What is the 30 day retention rate of the feature? How often are users turning it off and on? To accomplish these use cases we need a data model that tracks historical state:
| id | feature_x_enabled | valid_from | valid_to | is_current |
|---|---|---|---|---|
| 1 | true | 2019-01-01 12:14:23 | 2019-01-01 12:14:23 | true |
| 2 | true | 2019-01-01 15:21:45 | 2019-01-02 05:20:00 | false |
| 2 | false | 2019-01-02 05:20:00 | true |
This is known as a Type 2 dimensional model. In this post, I’ll show how you can create these data models using modern ETL tooling like PySpark and dbt (data build tool).
Background & Motivation
I currently work at Shopify as a data scientist in the International product line. Our product line is focused on adapting and scaling our product around the world. One of the first major efforts we undertook was translating Shopify’s admin in order to make our software available to use in multiple languages other than English.
![]()
At Shopify, data scientists work across the full stack - from data sourcing and instrumentation, to data modelling, dashboards, analytics and machine learning based products. As a product data scientist, I was responsible for understanding how our translated versions of the product were performing. How many users were adopting them? How was adoption changing over time? Were they retaining the new language, or switching back to English? If we defaulted a new user from Japan into Japanese, were they more likely to become a paying customer than if they were first exposed to the product in English and given the option to switch? The first step in the process of answering all these questions was figuring out how our data could be sourced or instrumented, and then eventually modelled into a format that allowed me to answer these questions.
The functionality to decide which language to render Shopify in is based on the language setting our engineers had added to the users data model. Also living in this model were a bunch of other fields we will ignore.
| id | language | … | created_at | updated_at |
|---|---|---|---|---|
| 1 | en | 2019-01-01 12:14:23 | 2019-06-01 07:15:03 | |
| 2 | ja | 2019-02-02 11:00:35 | 2019-02-02 11:00:35 | |
| … | … | … | … | … |
So User 1 would experience the Shopify admin in English, User 2 in Japanese, etc.. Like most data models powering Shopify’s software, the users model is a Type 1 dimension. Each time a user changes their language, or any other setting, the record gets updated in place. As I alluded to above, this data model format doesn’t allow us to answer many of our questions as they involve knowing what language a given user was using at a particular point in time. Instead, I needed a data model that tracked user’s languages over time. There are several ways to approach this problem.
Options for tracking state
Modify core application model design
In an ideal world (from an analyst’s perspective), the core application database model will be designed to track state. Rather than having a record be updated in place, the new settings are instead appended as a new record. Because the data is tracked directly in the source of truth, you can fully trust its accuracy.
If you’re working closely with engineers prior to the launch of a product or new feature, you can advocate for the need for tracking historical state and have them build the data model accordingly. However, you will often run into two challenges with this approach:
- Engineers will be very reluctant to change the data model design to support analytical use cases. They want the application to be as performant as possible (as should you), and having a data model which keeps all historical state is not conducive to that.
- Most of the time, new features or products are built on top of pre-existing data models. As a result, modifying an existing table design to track history will come with an expensive and risky migration process, along with the aforementioned performance concerns.
In the user language scenario discussed above, the language field was added to the pre-existing users model, and updating this model design was out of the question.
Stitch together database snapshots
At most technology companies, snapshots of application database tables are extracted into the data warehouse or data lake. At Shopify, we have a system that extracts newly created or updated records from the application databases on a fixed schedule.

Using these snapshots, one could leverage them as an input source for building a Type 2 dimension. However, given the fixed schedule nature of the data extraction system, it is possible that you will miss updates happening between one extract and the next.
If you are leveraging dbt for your data modelling, and are comfortable with only capturing events whenever snapshots are taken and your dbt job runs, you can leverage their nice built-in solution for building Type 2’s from snapshots!
Add database event logging
Another alternative is to add a new event log. Each newly created or update record is stored in this log. At Shopify, we rely heavily on Kafka as a pipeline for transferring real time data between our applications and data land, which makes it an ideal candidate for implementing such a log.
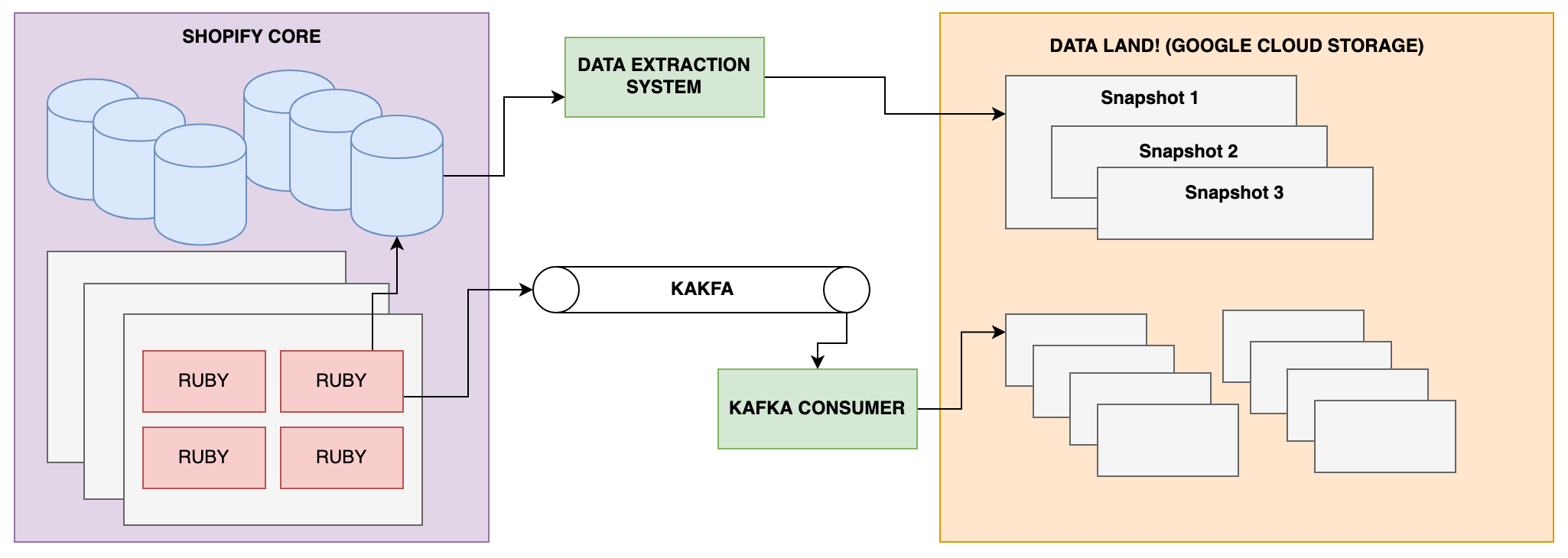
If you work closely with engineers, or are comfortable working in your application codebase, you can get new logging in place that will stream any new or updated record to Kafka. Shopify is built on the Ruby on Rails web framework. Rails has something called “Active Record Callbacks”, which allow you to trigger logic before or after an alternation of an object’s (read “database record’s”) state. For our use case, we can leverage the after_commit callback to log a record to Kafka after it has been successfully created or updated in the application database.
class User < ApplicationRecord
after_commit :log_record_change
def log_record_change
# produce a copy of the record to Kafka after the record has been
# successfully updated or created in the database (monorail is the
# name of a custom Kafka producer library we use at Shopify)
Monorail.produce(
'user_update', # kafka schema name
id: id,
language: language,
created_at: created_at,
updated_at: updated_at
)
end
end
While this option isn’t perfect, and comes with a host of other caveats I will discuss later, I ended up choosing it for this use case as it was the quickest and easiest solution to implement that provided the required granularity.
Type 2 modelling recipes
Below, I’ll walk through some recipes for building Type 2 dimensions from the event logging option discussed above. We’ll stick with our example of modelling user’s languages over time.
Scenario 1: event logging is present from day 1
Let’s start with the simple case where we’ve added event logging to our database model from day 1 (i.e. when the table was first created). Here’s an example of what our user_update event log would look like:
| id | language | created_at | updated_at |
|---|---|---|---|
| 1 | en | 2019-01-01 12:14:23 | 2019-01-01 12:14:23 |
| 2 | en | 2019-02-02 11:00:35 | 2019-02-02 11:00:35 |
| 2 | fr | 2019-02-02 11:00:35 | 2019-02-02 12:15:06 |
| 2 | fr | 2019-02-02 11:00:35 | 2019-02-02 13:01:17 |
| 2 | en | 2019-02-02 11:00:35 | 2019-02-02 14:10:01 |
This log describes the full history of the users data model.
- User 1 gets created at
2019-01-01 12:14:23with English as the default language - User 2 gets created at
2019-02-02 11:00:35with English as the default language - User 2 decides to switch to French at
2019-02-02 12:15:06 - User 2 changes some other setting that is tracked in the
usersmodel at2019-02-02 13:01:17 - User 2 decides to switch back to English at
2019-02-02 14:10:01
Our goal is to transform this event log into a Type 2 dimension that looks like this:
| id | language | valid_from | valid_to | is_current |
|---|---|---|---|---|
| 1 | en | 2019-01-01 12:14:23 | true | |
| 2 | en | 2019-02-02 11:00:35 | 2019-02-02 12:15:06 | false |
| 2 | fr | 2019-02-02 12:15:06 | 2019-02-02 14:10:01 | false |
| 2 | en | 2019-02-02 14:10:01 | true |
We can see that the current state for all users can easily be retrieved with a SQL query that filters for WHERE is_current. These records also have a null value for the valid_to column, since they are still in use. However, it is common practice to fill these nulls with something like the timestamp at which the job last ran, since the actual values may have changed since then.
PySpark
Due to Spark’s ability to scale to massive datasets, we use it at Shopify for building our data models that get loaded to our data warehouse. To avoid the mess that comes with installing Spark on your machine, I’ll leverage a pre-built docker image with PySpark and Jupyter notebook pre-installed. If you want to play around with these examples yourself, you can pull down this docker image with docker pull jupyter/pyspark-notebook:c76996e26e48 and then run docker run -p 8888:8888 jupyter/pyspark-notebook:c76996e26e48 to spin up a notebook where you can run PySpark locally.
We’ll start with some boiler plate code to create a Spark dataframe containing our sample of user update events.
from datetime import datetime as dt
from pyspark import SparkConf, SparkContext, SQLContext
from pyspark.sql import functions as F
import pyspark.sql.types as T
from pyspark.sql.window import Window
sc = SparkContext(appName="local_spark", conf=SparkConf())
sqlContext = SQLContext(sparkContext=sc)
def get_dt(ts_str):
return dt.strptime(ts_str, '%Y-%m-%d %H:%M:%S')
user_update_rows = [
(1, "en", get_dt('2019-01-01 12:14:23'), get_dt('2019-01-01 12:14:23')),
(2, "en", get_dt('2019-02-02 11:00:35'), get_dt('2019-02-02 11:00:35')),
(2, "fr", get_dt('2019-02-02 11:00:35'), get_dt('2019-02-02 12:15:06')),
(2, "fr", get_dt('2019-02-02 11:00:35'), get_dt('2019-02-02 13:01:17')),
(2, "en", get_dt('2019-02-02 11:00:35'), get_dt('2019-02-02 14:10:01')),
]
user_update_schema = T.StructType([
T.StructField('id', T.IntegerType()),
T.StructField('language', T.StringType()),
T.StructField('created_at', T.TimestampType()),
T.StructField('updated_at', T.TimestampType()),
])
user_update_events = sqlContext.createDataFrame(user_update_rows, schema=user_update_schema)
With that out of the way, the first step is to filter our input log to only include records where the columns of interest were updated. With our event instrumentation, we log an event whenever any record in the users model is updated. For our use case, we only care about instances where the user’s language was updated (or created for the first time). It’s also possible that you get duplicate records in your event logs, since Kafka clients typically support “at-least-once” delivery. The code below will also filter out these cases.
window_spec = Window.partitionBy('id').orderBy('updated_at')
change_expression = (F.col('row_num') == F.lit(1)) | (F.col('language') != F.col('prev_language'))
job_run_time = F.lit(dt.now())
user_language_changes = (
user_update_events
.withColumn(
'prev_language',
F.lag(F.col('language')).over(window_spec)
)
.withColumn(
'row_num',
F.row_number().over(window_spec)
)
.where(change_expression)
.select(['id', 'language', 'updated_at'])
)
user_language_changes.show()
We now have something that looks like this:
| id | language | updated_at |
|---|---|---|
| 1 | en | 2019-01-01 12:14:23 |
| 2 | en | 2019-02-02 11:00:35 |
| 2 | fr | 2019-02-02 12:15:06 |
| 2 | en | 2019-02-02 14:10:01 |
The last step is fairly simple. We produce one record per period for which a given language was enabled.
user_language_type_2_dimension = (
user_language_changes
.withColumn(
'valid_to',
F.coalesce(
F.lead(F.col('updated_at')).over(window_spec),
# fill nulls with job run time
# can also use timestamp of your last event
job_run_time
)
)
.withColumnRenamed('updated_at', 'valid_from')
.withColumn(
'is_current',
F.when(F.col('valid_to') == job_run_time, True).otherwise(False)
)
)
user_language_type_2_dimension.show()
| id | language | valid_from | valid_to | is_current |
|---|---|---|---|---|
| 1 | en | 2019-01-01 12:14:23 | 2020-05-23 00:56:49 | true |
| 2 | en | 2019-02-02 11:00:35 | 2019-02-02 12:15:06 | false |
| 2 | fr | 2019-02-02 12:15:06 | 2019-02-02 14:10:01 | false |
| 2 | en | 2019-02-02 14:10:01 | 2020-05-23 00:56:49 | true |
dbt
dbt (data build tool) is an open source tool that lets you build new data models in pure SQL. It’s a tool we are currently exploring using at Shopify as an alternative to modelling in PySpark, which I am really excited about. When writing PySpark jobs, you’re typically taking SQL in your head, and then figuring out how you can translate it to the PySpark API. Why not just build them in pure SQL? dbt lets you do exactly that:
WITH
-- create our sample data
user_update_events (id, language, created_at, updated_at) AS (
VALUES
(1, 'en', timestamp'2019-01-01 12:14:23', timestamp'2019-01-01 12:14:23'),
(2, 'en', timestamp'2019-02-02 11:00:35', timestamp'2019-02-02 11:00:35'),
(2, 'fr', timestamp'2019-02-02 11:00:35', timestamp'2019-02-02 12:15:06'),
(2, 'fr', timestamp'2019-02-02 11:00:35', timestamp'2019-02-02 13:01:17'),
(2, 'en', timestamp'2020-01-01 15:05', timestamp'2019-02-02 14:10:01')
),
users_with_previous_state AS (
SELECT
id,
language,
updated_at,
LAG(language) OVER (PARTITION BY id ORDER BY updated_at ASC) AS prev_language,
ROW_NUMBER() OVER (PARTITION BY id ORDER BY updated_at ASC) AS row_num
FROM
user_update_events
),
-- filter to instances where the column of interest (language) actually changed
-- or we are seeing a user record for the first time
user_language_changes AS (
SELECT
*
FROM
users_with_previous_state
WHERE
row_num=1
OR language <> prev_language
),
-- build the type 2!
user_language_type_2_dimension_base AS (
SELECT
id,
language,
updated_at AS valid_from,
LEAD(updated_at) OVER (PARTITION BY id ORDER BY updated_at ASC) AS valid_to
FROM
user_language_changes
)
-- fill "valid_to" nulls with job run time
-- or, you could instead use the timestamp of your last update event/extract
SELECT
id,
language,
valid_from,
COALESCE(valid_to, CURRENT_TIMESTAMP) AS valid_to,
CASE
WHEN valid_to IS NULL THEN True
ELSE False
END AS is_current
FROM
user_language_type_2_dimension_base
Scenario 2: event logging is added to an existing model
The example outlined above is the ideal scenario: we can solely leverage the user_update event log since this has recorded all changes since day 1. Unfortunately, this is not the common case. Usually we have an existing data model where we want to start tracking changes. To handle this, we need to save a static snapshot of the table, and then only consider user updates that occurred after that snapshot was taken.
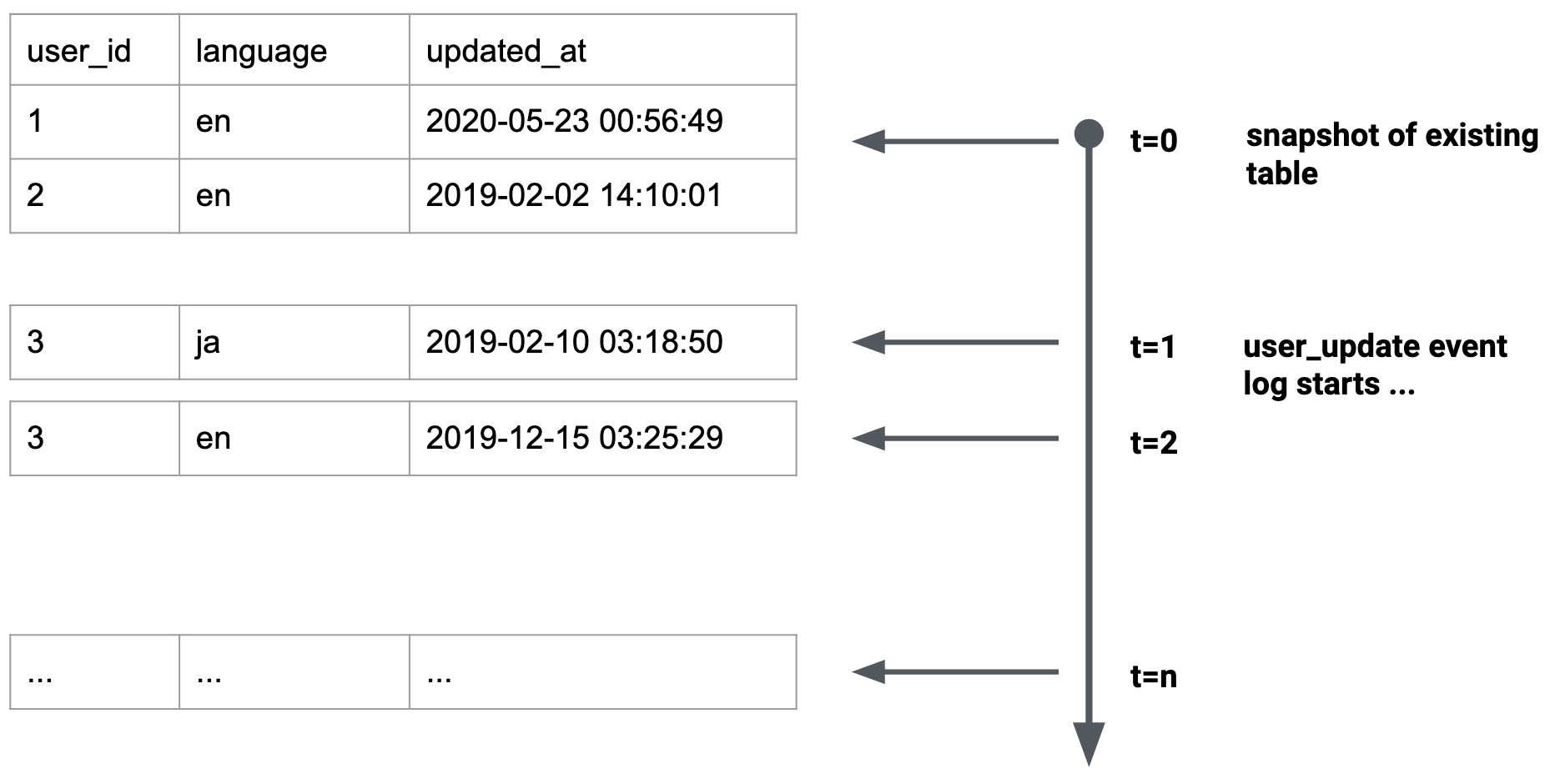
Once you have these two data sources, you can simply union them into a single log, and then follow the same recipes used above.
Gotchas, lessons learned & the path forward
I’ve leveraged the approaches outlined above with multiple data models now. Here are a few of the things I’ve learned along the way:
- It took us a few tries before we landed on the approach outlined above. In some initial implementations, we were logging the record changes before they had been successfully committed to the database, which resulted in some mismatches in the downstream Type 2 models. Since then, we’ve been sure to always leverage the
after_commitcallback based approach. - There are other pitfalls with logging changes from within the code:
- Your event logging becomes susceptible to future code changes (i.e. an engineer refactors some code and removes the
after_commitcall). These are rare, but can happen. A good safeguard against this is to leverage tooling like the CODEOWNERS file, which notifies you when a particular part of the codebase is being changed. - You may miss record updates that are not triggered from within the application code. Again, these are rare, but it is possible to have an external process that is not using the Rails
Usermodel when making changes to records in the database.
- Your event logging becomes susceptible to future code changes (i.e. an engineer refactors some code and removes the
- It is possible to lose some events in the Kafka process. For example, if one of the Shopify servers running the Ruby code were to fail before the event was successfully emitted to Kafka, you would lose that update event. Same thing if Kafka itself were to go down. Again, rare. But nonetheless, something you should be willing to live with.
- If deletes will occur in a particular data model, you need to implement a way to handle this. Otherwise, the delete events will be indistinguishable from normal create or update records with the logging setup I showed above.
- One way around this is to have the engineers modify the table design to use soft deletes instead of hard deletes.
- Alternatively, you can add a new field to your Kafka schema and log the type of event that triggered the change, i.e. (
create,updateordelete), and then handle accordingly in your Type 2 model code.
This has been an iterative process to figure out, and takes investment from both data and engineering to successfully implement. With that said, we have found the analytical value of the resulting Type 2 models well worth the upfront effort.
Looking ahead, there’s an ongoing project at Shopify by one of our data engineering teams to store the MySQL binary logs (binlogs) in data land. Binlogs are a much better source for a log of data modifications, as they are directly tied to the source of truth (the MySQL database), and are much less susceptible to data loss than the Kafka based approach. With binlog extractions in place, you don’t need to add separate Kafka event logging to every new model as changes will be automatically tracked for all tables. You don’t need to worry about code changes or other processes making updates to the data model since the binlogs will always reflect the changes made to each table. I am optimistic that with binlogs as a new, more promising source for logging data modifications, along with the recipes outlined above, we can produce Type 2s out of the box for all new models. Everybody gets a Type 2!
Appendix: SQL Query Recipes
Once we have our data modelled as a Type 2 dimension, there are a number of questions we can start easily answering:
/*
The following queries were run in Postgres version 11.5
user_language_type_2_dimension was created using the mock data from above.
*/
-- How many users are currently using Japanese?
SELECT
COUNT(*) AS num_users
FROM
user_language_type_2_dimension
WHERE
is_current
AND language='ja'
;
-- How many users were using Japanese 30 days ago?
SELECT
COUNT(*) AS num_users
FROM
user_language_type_2_dimension
WHERE
CURRENT_DATE - INTERVAL '30' DAY >= valid_from
AND CURRENT_DATE - INTERVAL '30' DAY < valid_to
AND language='ja'
;
-- How many users per language, per day?
WITH
-- dynamically generate a distinct list of languages
-- based on what is actually in the model
all_languages AS (
SELECT
language
FROM
user_language_type_2_dimension
GROUP BY 1
),
-- generate a range of dates we are interested in
-- leverage database's built in calendar functionality
-- if you don't have a date_dimension in your warehouse
date_range AS (
SELECT
date::date AS dt
FROM
GENERATE_SERIES(DATE'2019-01-01', CURRENT_DATE, INTERVAL '1' DAY) as t(date)
)
SELECT
dr.dt,
al.language,
COUNT(DISTINCT ld.id) AS num_users
FROM
date_range AS dr
CROSS JOIN all_languages AS al
LEFT JOIN user_language_type_2_dimension AS ld
ON dr.dt >= ld.valid_from
AND dr.dt < ld.valid_to
AND al.language=ld.language
GROUP BY 1,2
;
-- What is the 30-day retention rate of each language?
WITH
user_languages AS (
SELECT
id,
language,
MIN(valid_from) AS first_enabled_at,
MIN(valid_from) + INTERVAL '30' DAY AS first_enabled_at_plus_30d
FROM
user_language_type_2_dimension
GROUP BY 1,2
),
user_retention_inds AS (
SELECT
ul.id,
ul.language,
first_enabled_at_plus_30d,
CASE
WHEN ld.id IS NOT NULL THEN 1
ELSE 0
END AS still_enabled_after_30d
FROM
user_languages AS ul
LEFT JOIN user_language_type_2_dimension AS ld
ON ul.first_enabled_at_plus_30d >= ld.valid_from
AND ul.first_enabled_at_plus_30d < ld.valid_to
AND ul.language=ld.language
AND ul.id=ld.id
)
SELECT
language,
COUNT(*) AS num_users_enabled_language_ever,
100.0*SUM(still_enabled_after_30d)/COUNT(*) AS language_30d_retention_rate
FROM
user_retention_inds
WHERE
-- only consider users where 30 days have passed since they enabled the language
first_enabled_at_plus_30d < CURRENT_DATE
GROUP BY 1
;