
Data templates with pydantic
Motivation
When building & testing data-heavy applications, you need to be able to easily generate lots of different sample data to test against. At Shopify, we have an ETL framework built on top of PySpark. One of my favourite things about it is this neat testing utility called DataTemplate (shoutout to Jason White who first added this back in 2016!).
You generally use a DataTemplate to construct new pytest fixtures, which can then be used in your downstream tests.
from my_pipeline import pipeline, INPUT_CONTRACT
import DataTemplate
@pytest.fixture
def input_template():
default_record = {
'id': 1,
'created_at': datetime(2020, 1, 1),
'updated_at': datetime(2020, 2, 1),
'locale': 'en-US',
}
# INPUT_CONTRACT is based off a custom data "schema" class
# we use. It does things like define the data type of each
# field, and whether or not they can be nullable
schema = INPUT_CONTRACT
return DataTemplate(schema, default_record)
With this fixture, we can now easily generate a dataframe with a bunch of rows:
def test_pipeline(input_template):
sample_input_df = input_template.to_dataframe([
{}, # will just use the default record defined above
{'id': 2}, # id will be 2, all other fields will use default values
])
output = pipeline.run(sample_input_df)
In the snippet above, sample_input_df will be a new PySpark dataframe with 2 records. There are two great things going on under the hood here that make DataTemplate truly magical.
- Defaults values. Often times, you only want to introduce minor perturbations to a base record, without having to re-specify the entire thing. With
DataTemplate, I don’t need to explicitly define every field each time. I can rapidly create new records by only changing the fields that are relevant to my current use case. This is especially useful when you are dealing with wide data, which is often the case. - Data validation against a schema. Behind the scenes, the
DataTemplateclass validates each record (dictionary) I provide against the specified schema (or “contract”). This helps catch errors in your test data and ensures it will conform to a certain standard.
DataTemplate is incredibly useful but is tightly coupled to our PySpark ETL framework. Recently, I’ve been working on a data heavy application that doesn’t use Spark. Instead, I’m pulling data in & out of a Postgres database, processing it in memory with Pandas or standard Python data types, and occasionally using Dask when it doesn’t fit in memory. So how can we re-create this beauty?
DataTemplates with pydantic
pydantic is a Python library that lets you do data validation using Python type annotations.
from datetime import datetime
from typing import Optional
from pydantic import BaseModel
class User(BaseModel):
id: int = 1
first_name: str = "Foo"
last_name: Optional[str] = "Bar"
created_at: datetime = datetime(2020, 1, 1)
updated_at: datetime = datetime(2020, 1, 1)
We can use pydantic to accomplish both things I listed above: default values & data validation. In the User model I define the fields, their data types, their default values, and whether or not they can be nullable (only last_name can be set to None, even though I have provided a non-null default value). We can then use this class generate new records:
# Only change id & first_name
>>> User(id=2, first_name="Foo Baz")
User(id=2, first_name='Foo Baz', last_name='Bar',
created_at=datetime.datetime(2020, 1, 1, 0, 0),
updated_at=datetime.datetime(2020, 1, 1, 0, 0))
# Initialize from a dict
>>> User(**{'id': 2, 'first_name': 'Foo Baz'})
...same as above
# Just use the default values
>>> User()
User(id=1, first_name='Foo', last_name='Bar',
post_count=0, created_at=datetime.datetime(2020, 1, 1, 0, 0),
updated_at=datetime.datetime(2020, 1, 1, 0, 0))
# Get a dict back instead of a class
>>> User(id=3, updated_at=datetime(2020, 1, 2)).dict()
{'id': 3,
'first_name': 'Foo',
'last_name': 'Bar',
'created_at': datetime.datetime(2020, 1, 1, 0, 0),
'updated_at': datetime.datetime(2020, 1, 2, 0, 0)}
# yells at bad data
>>> User(id="John")
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
<ipython-input-325-ad2a6441a8eb> in <module>
----> 1 User(id="John")
~/Library/Caches/pypoetry/virtualenvs/IWOYYLRr-py3.7/lib/
python3.7/site-packages/pydantic/
main.cpython-37m-darwin.so in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for User
id
value is not a valid integer (type=type_error.integer)
Now, with < 30 lines of Python, we can re-create that DataTemplate magic ✨.
from typing import Any, Dict, List, Optional
import pandas as pd
from pydantic.main import ModelMetaclass
class DataTemplate:
def __init__(self, template: ModelMetaclass):
self.template: ModelMetaclass = template
def __repr__(self):
return f"DataTemplate({self.template().__dict__})"
def __str__(self):
return str(self.template())
@property
def default(self):
"""Return a single dict containing the default values"""
return self.template().dict()
def record(self, record: Optional[Dict] = None):
"""Generate a single dict from the template"""
if record is None:
record = {}
return self.template(**record).dict()
def records(self, records: List[Dict]) -> List[Dict]:
"""Generate a list of dicts conforming to the template"""
return [self.template(**record).dict() for record in records]
def dataframe(self, records: List[Dict]) -> Any:
"""Generate a pandas dataframe from a list of dicts"""
return pd.DataFrame(self.records(records))
To leverage the DataTemplate class, we just initialize it with our pydantic User model, and then we can start churning out new records.
# Initialize our class
>>> user_data_template = DataTemplate(User)
>>> user_data_template
DataTemplate({'id': 1, 'first_name': 'Foo', 'last_name': 'Bar',
'created_at': datetime.datetime(2020, 1, 1, 0, 0),
'updated_at': datetime.datetime(2020, 1, 1, 0, 0)})
# Generate a default value record via .default
>>> user_data_template.default
{'id': 1,
'first_name': 'Foo',
'last_name': 'Bar',
'created_at': datetime.datetime(2020, 1, 1, 0, 0),
'updated_at': datetime.datetime(2020, 1, 1, 0, 0)}
# Or via .record()
>>> user_data_template.record({})
{'id': 1,
'first_name': 'Foo',
'last_name': 'Bar',
'created_at': datetime.datetime(2020, 1, 1, 0, 0),
'updated_at': datetime.datetime(2020, 1, 1, 0, 0)}
# Create a slightly modified default record
>>> user_data_template.record({'id': 2})
{'id': 2,
'first_name': 'Foo',
'last_name': 'Bar',
'created_at': datetime.datetime(2020, 1, 1, 0, 0),
'updated_at': datetime.datetime(2020, 1, 1, 0, 0)}
# Create a list of new records
>>> user_data_template.records([
... {},
... {"id": 2},
... {"id": 3, "last_name": "Baz"}
... ])
[{'id': 1,
'first_name': 'Foo',
'last_name': 'Bar',
'created_at': datetime.datetime(2020, 1, 1, 0, 0),
'updated_at': datetime.datetime(2020, 1, 1, 0, 0)},
{'id': 2,
'first_name': 'Foo',
'last_name': 'Bar',
'created_at': datetime.datetime(2020, 1, 1, 0, 0),
'updated_at': datetime.datetime(2020, 1, 1, 0, 0)},
{'id': 3,
'first_name': 'Foo',
'last_name': 'Baz',
'created_at': datetime.datetime(2020, 1, 1, 0, 0),
'updated_at': datetime.datetime(2020, 1, 1, 0, 0)}]
# Generate a pandas dataframe
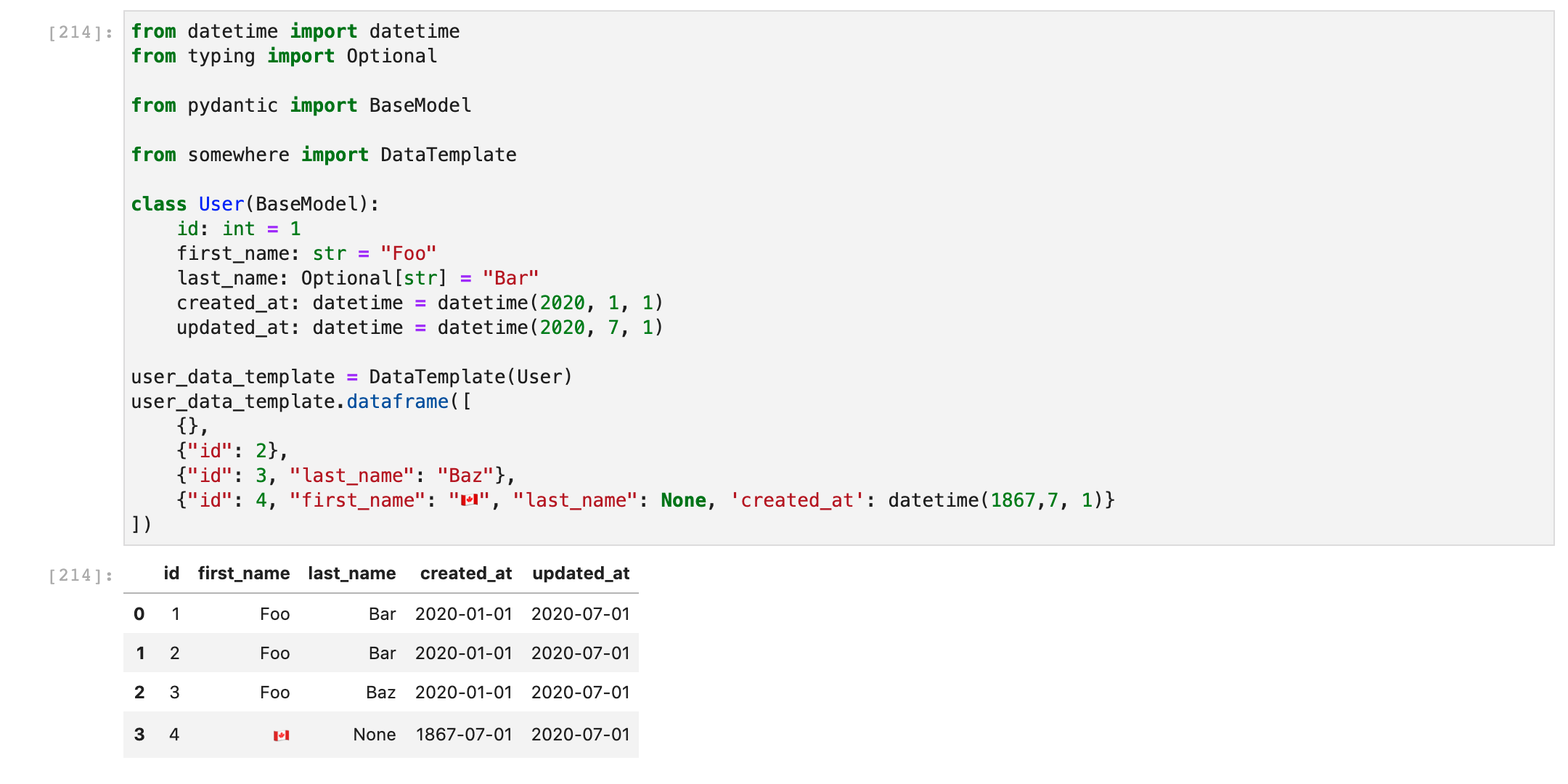
>>> user_data_template.dataframe([
... {},
... {"id": 2},
... {"id": 3, "last_name": "Baz"},
... {"id": 4, "first_name": "🇨🇦", "last_name": None, 'created_at': datetime(1867,7, 1)}
... ])
id first_name last_name created_at updated_at
0 1 Foo Bar 2020-01-01 2020-01-01
1 2 Foo Bar 2020-01-01 2020-01-01
2 3 Foo Baz 2020-01-01 2020-01-01
3 4 🇨🇦 None 1867-07-01 2020-01-01
Because DataTemplate is just calling your pydantic model, you get the same nice data validation & useful error messages as showed above:
>>> user_data_template.record({'id': "John"})
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
<ipython-input-356-47ca1872fcd8> in <module>
----> 1 user_data_template.record({'id': "John"})
<ipython-input-353-19d3fa068a02> in record(self, record)
92 if record is None:
93 record = {}
---> 94 return self.template(**record).dict()
95
96 def records(self, records: List[Dict]) -> List[Dict]:
~/Library/Caches/pypoetry/virtualenvs/IWOYYLRr-py3.7/lib/
python3.7/site-packages/pydantic/
main.cpython-37m-darwin.so in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for User
id
value is not a valid integer (type=type_error.integer)
Be sure to check out the pydantic docs to see all the other types of fields you can specify and the associated validations.
DataTemplate in action
Say we have some pipeline that is aggregating a few Pandas dataframes:
import pandas as pd
def get_user_post_count(users_df, posts_df):
# ... maybe some other stuff
return (
pd.merge(
users_df,
posts_df,
left_on="id",
right_on="user_id",
how="left",
suffixes=("_user", "_post"),
)
.groupby("id_user")
.agg(post_count=("id_post", "count"))
.reset_index()
.rename(columns={"id_user": "user_id"})
)
As I showed earlier, we can easily incorporate DataTemplate into our test suite as a pytest.fixture. Here’s an example of how you could test get_user_post_count:
from datetime import datetime
from typing import Optional
from pandas.testing import assert_frame_equal
from pydantic import BaseModel
import pytest
from somewhere import DataTemplate
from somewhere import get_user_post_count
@pytest.fixture
def user_data_template():
class User(BaseModel):
id: int = 1
first_name: str = "Foo"
last_name: Optional[str] = "Bar"
created_at: datetime = datetime(2020, 1, 1)
updated_at: datetime = datetime(2020, 1, 1)
return DataTemplate(User)
@pytest.fixture
def post_data_template():
class Post(BaseModel):
id: int = 1
user_id: int = 1
content: Optional[str]
created_at: datetime = datetime(2020, 1, 1)
updated_at: datetime = datetime(2020, 1, 1)
return DataTemplate(Post)
@pytest.fixture
def output_data_template():
class Output(BaseModel):
user_id: int = 1
post_count: int = 0
return DataTemplate(Output)
Above, I’ve created three test fixtures for each dataframe involved in the pipeline. In this scenario, I’m only using the pydantic models for the test cases, so I’ve nested them in the fixtures themselves. However, wherever possible, you should integrate these models into your actual pipeline so you can get the same data validation benefits at runtime and catch issues early on before they unknowingly percolate downstream.
Now we can easily use these fixtures in our test cases to quickly generate sample dataframes:
def test_get_user_post_count(user_data_template, post_data_template, output_data_template):
user_df = user_data_template.dataframe(
[
{"id": 1},
{"id": 2},
{"id": 3},
]
)
post_df = post_data_template.dataframe(
[
{"user_id": 1},
{"user_id": 1},
{"user_id": 1},
{"user_id": 2},
]
)
expected_output_df = output_data_template.dataframe(
[
{"user_id": 1, "post_count": 3},
{"user_id": 2, "post_count": 1},
{"user_id": 3},
]
)
actual_output_df = get_user_post_count(user_df, post_df)
assert_frame_equal(expected_output_df, actual_output_df)
Happy testing!